Robots.txt file
Robots.txt is a text file that contains parameters of the site indexing for web crawlers. It is usually used to make crawlers ignore certain pages in the search engine results.
To set up the search parameters for crawlers, go to Settings → SEO Settings.
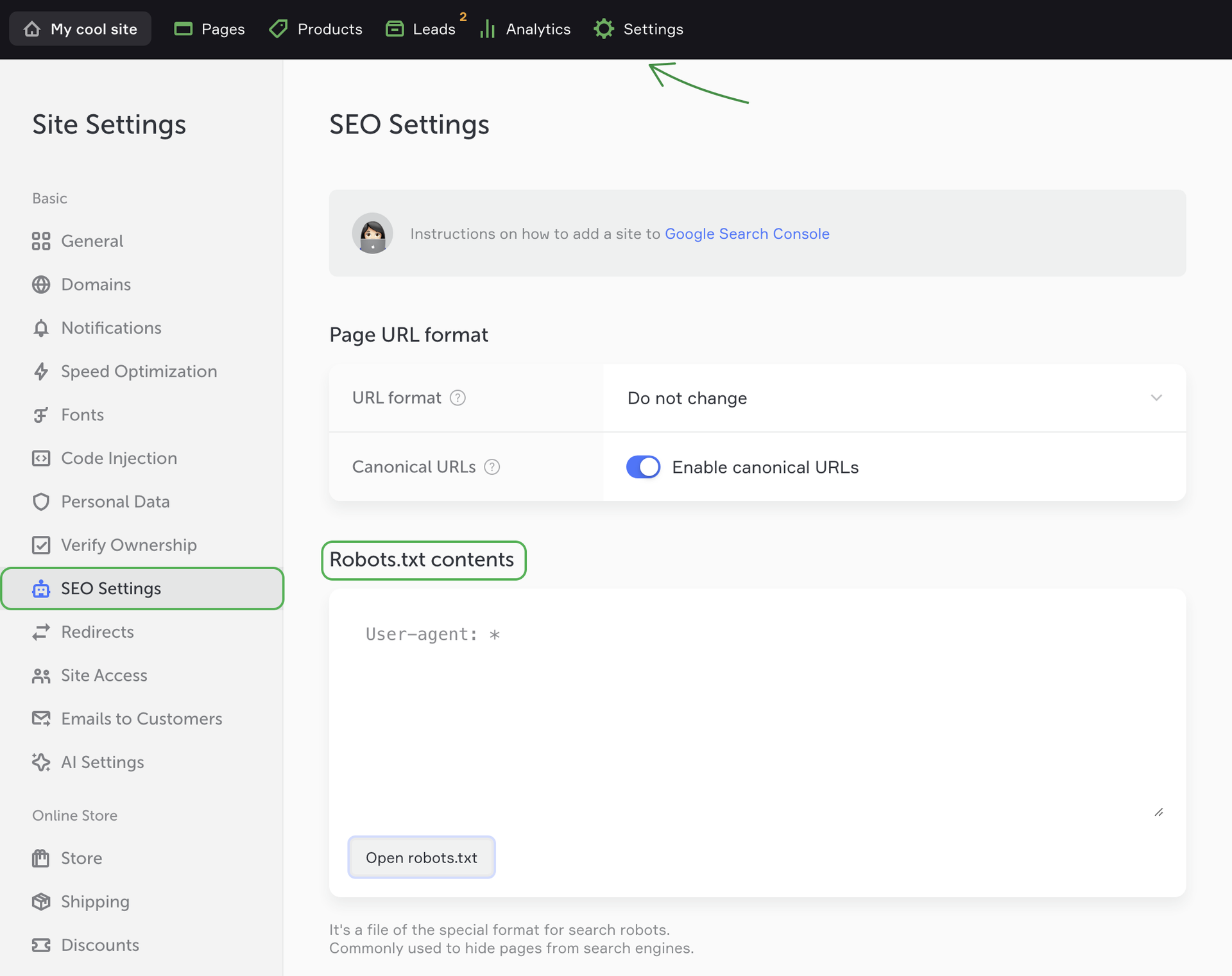
Editing your Robots.txt file
If you want to exclude the whole site from web indexing (i.e. to hide it from all search engines), copy the text below and paste to the File content field:
User-agent: *
Disallow: /
If you want to exclude only a separate page, copy:
Here /page/ is the URL of the page you need to hide from indexing.
To see the page URL, click Page settings on the upper panel and copy the page URL.
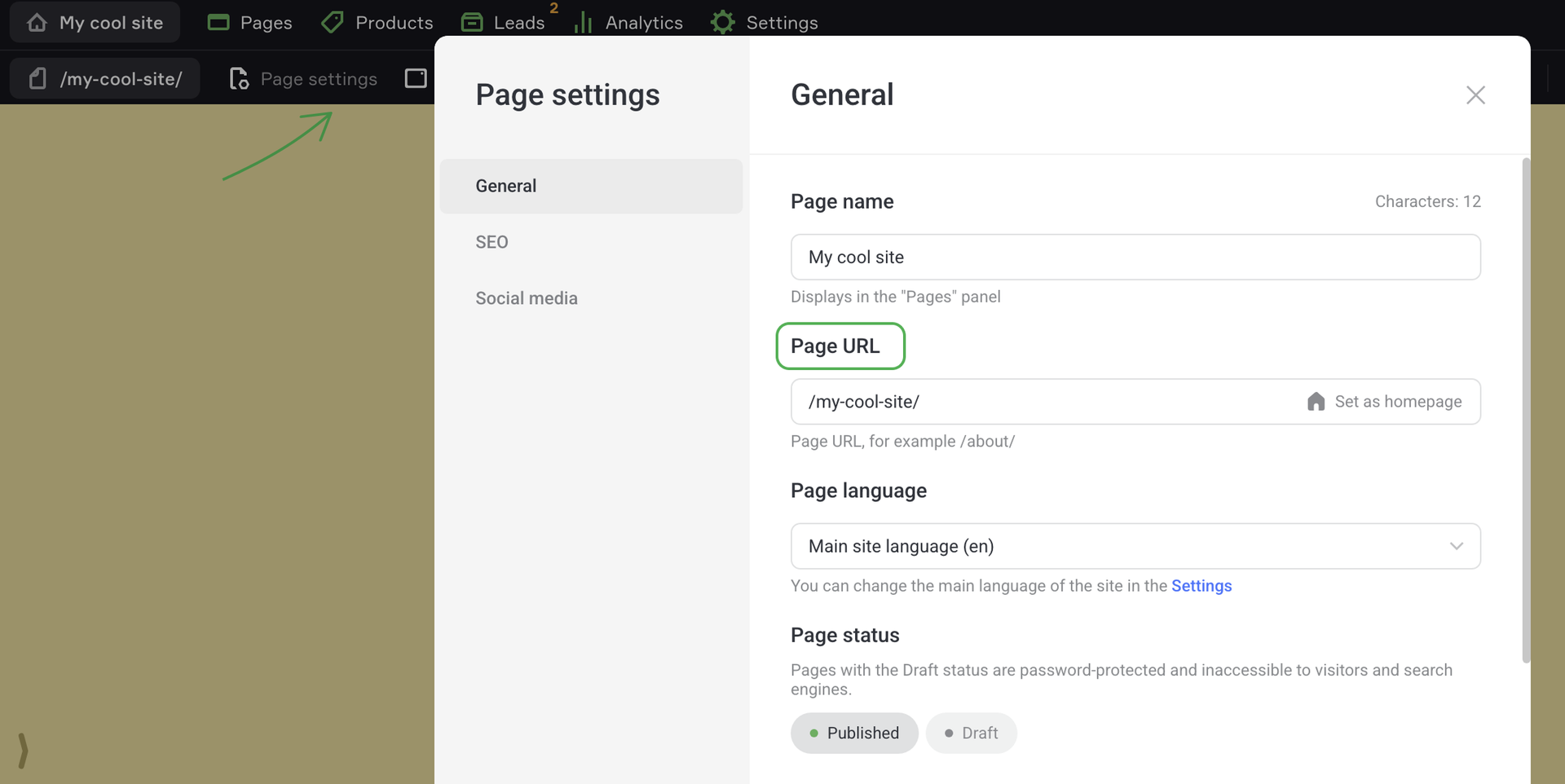
Copy the address in the Page URL and paste:
User-agent: *
Disallow: /page_copy2/
Learn more about creating a robots.txt file in this Google article.
Canonical URLs
If you have several pages with almost identical content or one page with multiple URLs, search engines may consider them as duplicates, which can negatively impact your site ranking.
If this occurs, a search engine chooses only one page to show in the search results. This page is called canonical.
To avoid this, the Enable canonical URLs toggle is active by default.